This is an Anki 2.0 plugin. I think i will update it to 2.1, but don’t know when i will get around to it. If you are impatient, you can of course do the update yourself. Please let me know which way you want your version published.
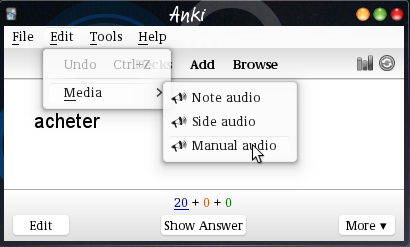
This add-on adds three menu items,
Edit/Media/Note audio
Edit/Media/Side audio
andEdit/Media/Manual audio
,
All three try to download audio in slightly different manners from a number of sources. It also adds a button to the edit card screens to download from there.
First start – Language
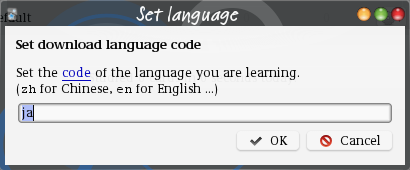
The first time you start Anki after downloading the add-on, a dialog will appear asking for a language code. Here you should select the language you are learning, not your native language.
When setting the language, use language codes. Do not use country domain names. For example, usejafor Japanese, notjp.
A list of audio codes can – unsurprisingly – be found at Wikipedia.
Setup – Models
Use the models the add-on brings along can be used for simple cards and new material.
Changes to existing models
When the already existing notes use a more complex model, this model should be modified instead. An audio field should be added to the model and the cards
Interested users can look at the detailed rules on field selection for hints on how to use more then one pronunciation per note, and how to create audio cards.
Downloading
When reviewing, select one of the three Edit/Media/Note audio
,
Edit/Media/Side audio
and Edit/Media/Manual audio
menu items to
download.
When editing or adding cards, click the megaphone button above the field edit list to do a manual download.
Side audio
Side audio loads audio that will appear on the currently visible side. During the review, it will hide the text it used to get the sounds. Use this while learning from your native language to the foreign language, or when trying to recognize spoken words.
The “t” key can be used as a shortcut for this download method.
Note audio
Note audio fetches sounds for all audio fields of the current note. During the review, the texts used to retrieve the sounds are shown.
Use “q” a short cut for this download method.
Manual audio
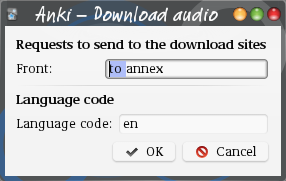
Manual audio mode opens a dialog showing all fields where files can be downloaded. The texts, as well as the language to use, can be changed before the request is send.
You can also use “Ctrl+t” to open the dialog. The “q” and “t” keys are used by the Dvorak keys add-on, too. When both are installed, the download shortcuts will not work, and a “hard” or “good” reply will be recorded.
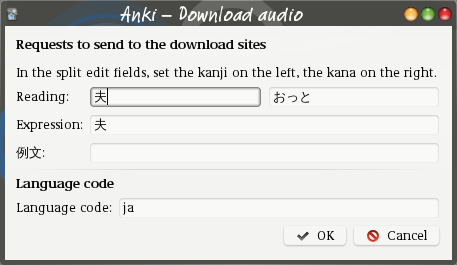
When learning Japanese, when there is a Reading
field,
the text used as request and shown in the dialog is split into the
base text and the reading. See the
split reading page for more details.
Along with the edit field or fields for the request text, the edit dialog also as a field to set the language code. This can be used to download in a language different from that set for the current deck, even when the tag is not set for the current note.
Review
When the add-on could not find anything to download, a brief notification appears.
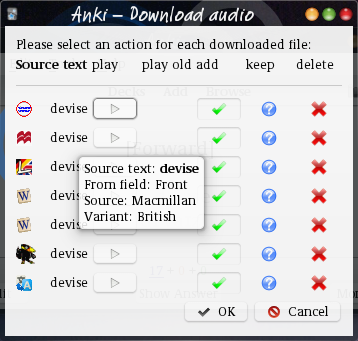
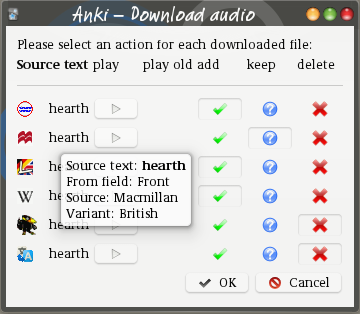
After a successful download, a dialog appears. It lists the retrieved audio clips, one per row. The icon for each shows the source, Hovering over the icon or the word shows some information about the file.
Each row has a number of buttons, one or two play buttons and three or four radio buttons.
The left (or only) play button plays the newly retrieved file. If there is a second play button, the field where the new audio clip will be added is not empty. Clicking this button plays the old field content.
To the right, there are three or four radio buttons. Select one for each line. They determine what happens to the downloaded file.
- The add check mark. When this button is down the audio clip will be added to the card. This is the normal thing to select for a good download, but when many files were downloaded, you may want to add only a few of them.
- The keep question mark icon. When this button is down, the add-on will neither add the file to the card nor delete it but keep it in the media collection folder. This means the file will show up as an unused medium and may be deleted during an unused media check.
- The delete cross mark button. When this button is down the audio clip will be deleted. This is the normal thing to do with a file you don’t like.
- There may be a blacklist skull-and-bones button. When this is down, the same file will be dropped in the future. See blacklist for more information.
Languages
Changing languages
After the start, the language code can be changed in the deck options, under the general tab. This can be done separately for each options group. Like this, it is possible to use different download languages with different decks. See also the Anki manual.
When a note has a tag in the form
(e.g. lang_<NN>
for
English, lang_en
for French), this language code is used for the
download.lang_fr
Supported languages
The languages this add-on supports depends on the languages of the dictionaries used.
At the moment, you can get pronunciations for
- Danish (
da) from Den Dasnke Ordbog - English (
en) from Macmillan Dictionary, Merriam-Webster, Oxford Advanced American Dictionary &c. - French (
fr) from Collins - German (
de) from BeoLingus and Duden - Icelandic (
is) from ISLEX - Italian (
it) from Collins - Japanese (
ja) from JapanesePod - Spanish (
es) from BeoLingus - Swedish (
sv) from Lexin
Google translate list over 60 languages for text translations. It seems unlikely that they offer text-to-speech services for more. The simplest way to see if GoogleTTS works for your target language is to send a request or two and see (hear) if you get a useful reply.
Lastly, Wiktionary is asked with any language code. The add-on may or may not find anything useful.
More information in the list of sites used.
Private use
These audio files can be freely downloaded without registering or agreeing to a license, but they keep the copyright of those providing them. While i see no problem with using them privately, re-publishing, for example by uploading a shared deck to AnkiWeb, is most likely prohibited by those rights.
Even words downloaded from Wiktionary should not simply be re-published. Those files are usually available under the Creative Commons Attribution/Share-Alike License, but the add-on does not correctly attribute the files to their authors. See the Wikimedia Terms of Use for details.
Do not publish decks with audio clips downloaded with this add-on without ensuring you have the rights to do so.
No bulk download
This add-on does not do bulk downloads. That is, there is no way to let it go through the whole collection and download something for every card. There are a few reasons for this:
- It appears that the Google TTS service throttles the number of replies it delivers when they requests are send too quickly. (At least the AwesomTTS add-on has code to work around this problem, needed or not.)
- As there may be many files downloaded for each word, i think the review of the downloaded material should not be skipped.
- This is especially true for JapanesePod, where you may want to blacklist some downloads.
- Contemplating the downloaded data when you get it note by note is also potentially useful in remembering the words.
Improvements
Bugs and other issues can be reported at the GitHub repository or the add-ons issue tracker.
Github pull requests with patches are welcome. The preferred way is to use
git-flow and create a feature branch off the
develop
branch.
Audio processing
The standard installation saves the files as they are received, which works well enough. Nothing more is needed.
But the add-on contains code to do simple audio processing:
- Normalizing the volume
- Clipping silence at the beginning and the end
- Changing the output format
This code is not used by default, as it requires an extra Python packages, PyDub. That depends on ffmpeg or libav. If either one is there, pydub can usually be installed via pip. Hackers that manage to do that may then want to take a look at the processors.
More ideas
Things that might be added in the future (but don’t hold your breath):
- Switch off the menu items when not reviewing.
- Automatically edit the information before the request is sent. I use
what i call
electric
cards for Japanese verbs, where the different forms are formed automatically. That means that the whole word doesn’t actually appear in the note. While it is no big problem to complete the word in theManual audio
dialog, the add-on could automatically add theる
for 一段動詞. This will most likely not by implemented any time soon. - More non-English talking dictionaries. Links welcome. Python files
welcome. Take a look at
downloadaudio/downloaders, write a new class derived fromAudioDownloaderand send me a pull request. Or just the.py-file. There are already quite a number of sources for English, so i will probably not add any more for that language.